
英语原文共 11 页,剩余内容已隐藏,支付完成后下载完整资料
R-FCN:通过对象检测
a
摘要
我们提出了基于区域的全卷积网络,以进行准确,高效的目标检测。与之前的基于区域的检测器(例如快速/快速R-CNN [6,18])多次应用昂贵的每个区域子网相比,我们的基于区域的检测器是完全卷积的,几乎所有计算都在整个图像上共享。为了实现此目标,我们提出了位置敏感得分图,以解决图像分类中的平移不变性与目标检测中的平移差异性之间的难题。因此,我们的方法自然可以采用完全卷积的图像分类器主干,例如最新的残差网络
(ResNets)[9],用于物体检测。我们在具有101层ResNet的PASCAL VOC数据集(例如2007年设置的83.6%mAP)上显示出竞争性结果。同时,我们的结果是在每幅图像170ms的测试时间速度下实现的,比Faster R-CNN的速度快2.5-20倍。代码在以下位置公开可用:https://github.com/daijifeng001/r-fcn。
1引言
兴趣区域(RoI)池化层[6]可以将用于对象检测的深层网络的普遍家族[8、6、18]划分为两个子网:(i)独立于共享的“完全卷积”子网RoI,以及(ii)不共享计算的RoI子网络。历史上,这种分解[8]是由开创性的分类架构(例如AlexNet [10]和VGG Nets [23])导致的,分类架构由两个子网组成,一个设计为卷积子网络,最后一个是空间池化层,然后是几个完全连接的(fc)层。因此,图像分类网络中的(最后)空间池化层自然变成了对象检测网络中的RoI池化层[8、6、18]。
但是,最新的图像分类网络,例如残差网络(ResNets)[9]和GoogLeNets [24、26],在设计上是完全卷积的。以此类推,在对象检测架构中使用所有卷积层来构建共享的卷积子网络似乎很自然,而在RoI方式的子网络中则没有隐藏层。但是,根据这项工作的经验研究,这种幼稚的解决方案的检测精度却大大低于网络的出色分类精度。为了解决这个问题,在ResNet论文[9]中,将Faster R-CNN检测器[18]的RoI池化层不自然地插入到两组卷积层之间-这会创建一个更深的RoI子网络,从而提高准确性。由于未共享的每RoI计算导致较低的速度成本。
我们认为,上述不自然的设计是由两难问题引起的:图像分类的翻译不变性增加,而对于目标检测则尊重翻译差异。一方面,图像级分类任务有利于翻译不变性-转移图像内的对象应该是无区别的。因此,最好的深度(完全)卷积体系结构尽可能平移不变,如ImageNet分类的主要结果所证明的那样
当Yi Li是Microsoft Research的实习生时,就完成了这项工作。
2
只有最后一层是完全连接的,在进行微调以进行对象检测时将其移除并替换。
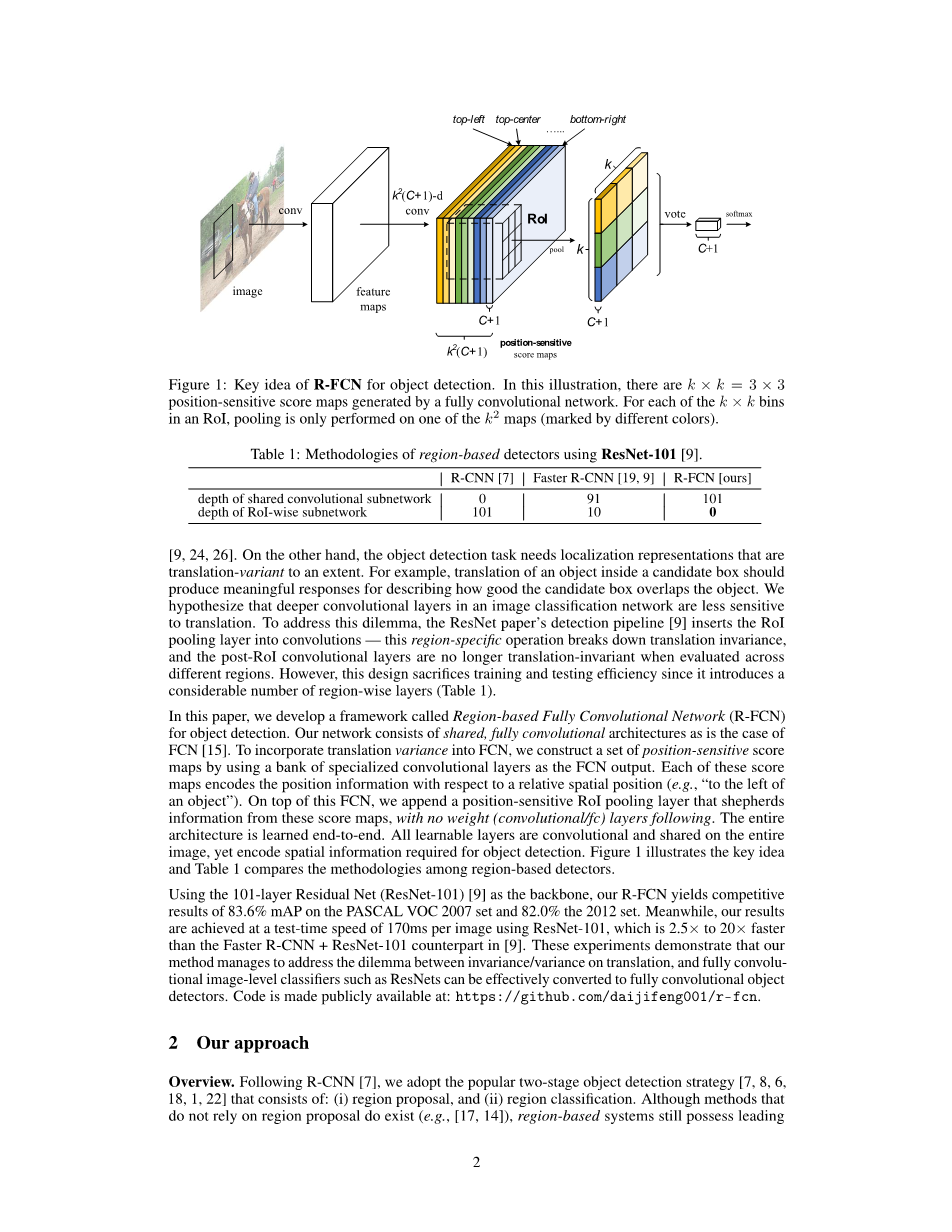
图1:R-FCN用于物体检测的关键思想。在该图中,有一个由全卷积网络生成的ktimes;k = 3times;3位置敏感分数图。对于RoI中的ktimes;k个bin中的每个bin,仅对k2个映射(用不同颜色标记)之一进行合并。
表1:使用ResNet-101 [9]的基于区域的探测器的方法。
[9,24,26]。另一方面,对象检测任务需要一定程度的翻译变化的本地化表示。例如,候选框内对象的平移应产生有意义的响应,以描述候选框与对象重叠的程度。我们假设图像分类网络中较深的卷积层对翻译的敏感性较低。为了解决这个难题,ResNet论文的检测管道[9]将RoI池层插入到卷积中-此特定于区域的操作可分解平移不变性,并且在不同区域进行评估时,RoI后卷积层不再具有平移不变性。但是,这种设计牺牲了训练和测试效率,因为它引入了大量的区域层(表1)。
在本文中,我们开发了一个称为“基于区域的全卷积网络(R-FCN)”的框架用于对象检测。我们的网络由共享的,完全卷积的体系结构组成,例如FCN [15]。为了将翻译差异纳入FCN,我们通过使用一组特殊的卷积层作为FCN输出来构造一组位置敏感的得分图。这些得分图中的每一个都相对于相对空间位置(例如,“在对象的左侧”)对位置信息进行编码。在此FCN的顶部,我们附加了位置敏感的RoI合并层,该层从这些得分图中扩展了信息,而后面没有权重(卷积/ fc)层。整个架构是端到端学习的。所有可学习的层都是卷积的,并且在整个图像上共享,但是对对象检测所需的空间信息进行编码。图1说明了关键思想,表1比较了基于区域的检测器之间的方法。
使用101层残差网(ResNet-101)[9]作为主干,我们的R-FCN在PASCAL VOC 2007装置上的竞争性结果为83.6%mAP,在2012年装置中为82.0%。同时,我们使用ResNet-101在每张图像170ms的测试时间速度下获得了我们的结果,速度提高了2.5倍至20倍比[9]中的Faster R-CNN ResNet-101更快。这些实验表明,我们的方法设法解决平移不变/方差之间的难题,并且可以将完全卷积的图像级分类器(如ResNets)有效地转换为完全卷积的对象检测器。代码在以下位置公开可用:https://github.com/daijifeng001/r-fcn。
1我们的方法
概述。遵循R-CNN [7],我们采用了流行的两阶段目标检测策略[7、8、6、18、1、22],该策略包括:(i)区域建议和(ii)区域分类。尽管确实存在不依赖于区域提议的方法(例如[17、14]),但基于区域的系统仍然拥有领先的.
图2:R-FCN的总体架构。区域提议网络(RPN)[18]提出候选RoI,然后将其应用于得分图。所有可学习的权重层都是卷积的,并在整个图像上进行计算;每RoI的计算成本可忽略不计。
在几个基准上的准确性[5、13、20]。我们通过区域提议网络(RPN)[18]提取候选区域,它本身就是一个完全卷积的体系结构。按照[18],我们在RPN和R-FCN之间共享功能。图2显示了该系统的概述。
给定建议区域(RoI),R-FCN体系结构旨在将RoI分为对象类别和背景。在R-FCN中,所有可学习的权重层都是卷积的,并在整个图像上进行计算。最后一个卷积层为每个类别生成一组k2个位置敏感得分图,因此具有一个k2(C 1)通道输出层,其中包含C个对象类别(背景为 1)。 k2个得分图库对应于描述相对位置的ktimes;k空间网格。例如,在ktimes;k = 3times;3的情况下,这9个得分图对对象类别的{top-left,top-center,top-right,...,bottom-right}进行编码。
R-FCN以位置敏感的RoI池层结束。该层汇总最后一个卷积层的输出,并为每个RoI生成分数。与[8,6]不同,我们的位置敏感RoI层进行选择性池化,并且ktimes;k bin中的每一个都聚集来自ktimes;k得分图库中仅一个得分图的响应。通过端到端的训练,该RoI层引导最后的卷积层学习专门的位置敏感得分图。图1说明了这个想法。图3和图4展示了一个示例。详细介绍如下。
骨干架构。 R-FCN的化身基于ResNet-101 [9],尽管其他网络[10,23]也适用。 ResNet-101具有100个卷积层,然后是全局平均池和1000个类的fc层。我们删除了平均池化层和fc层,仅使用卷积层来计算特征图。我们使用[9]的作者发布的ResNet-101,在ImageNet [20]上进行了预训练。 ResNet-101中的最后一个卷积块是2048-d,我们将随机初始化的1024-d 1times;1卷积层附加到减小尺寸(准确地说,这会使表1中的深度增加1)。然后,我们将应用k2(C 1)通道卷积层以生成得分图,如下所述。
位置敏感得分图和位置敏感RoI池。为了将位置信息显式编码到每个RoI中,我们通过规则网格将每个RoI矩形划分为ktimes;k个bin。对于大小为wtimes;h的RoI矩形,bin的大小为6]。在我们的方法中,最后一个卷积层被构造为每个类别产生k2得分图。在第(i,j)个bin(0le;i,jle;k minus; 1)内,我们定义了位置敏感的RoI合并操作,该操作仅在第(i,j)个得分图上进行合并:
rc(i,j |Theta;)= X zi,j,c(x x0,y y0 |Theta;)/ n。 (1)
(x,y)isin;bin(i,j)
这里rc(i,j)是第c个类别在第(i,j)个bin中的汇总响应,zi,j,c是k2(C 1)得分图中的一个得分图,( x0,y0)表示RoI的左上角,n是像素仓中的像素数,Theta;表示网络的所有可学习参数。第(i,j)个bin跨度为和。等式(1)的操作如图1所示,其中颜色代表一对(i,j)。等式(1)执行平均池化(正如我们在本文中所使用的),但是也可以进行最大池化。
然后,k2位置敏感分数在RoI上投票。在本文中,我们简单地通过对得分进行平均来投票,从而为每个RoI生成一个(C 1)维向量:rc(Theta;)= Pi,j rc(i,j |Theta;)。然后,我们跨类别计算softmax响应:。它们用于评估训练过程中的交叉熵损失,并用于在推理过程中对RoI进行排名。
我们以类似的方式进一步解决边界框回归[7,6]。除了上面的k2(C 1)-d卷积层之外,我们还添加了一个同级4k2-d卷积层用于边界框回归。对这组4k2映射执行位置敏感的RoI合并,为每个RoI生成4k2-d向量。然后通过平均投票将其汇总为一个4-d向量。在[6]中的参数化之后,此4-d向量将边界框参数化为t =(tx,ty,tw,th)。我们注意到,为简单起见,我们执行了与类无关的包围盒回归,但适用于特定于类的对应对象(即具有4k2C-d输出层的类)。
位置敏感分数图的概念部分受到[3]的启发,该文献开发了用于实例级语义分割的FCN。我们进一步介绍了位置敏感的RoI池层,该层扩展了得分图的学习以用于对象检测。 RoI层之后没有可学习的层,可实现几乎免费的区域级计算,并加快了训练和推理的速度。
训练。利用预先计算的区域建议,可以轻松地端到端训练R-FCN体系结构。根据[6],我们在每个RoI上定义的损失函数是交叉熵损失和盒回归损失的总和:L(s,tx,y,w,h)= Lcls(sc lowast;) lambda;[c lowast; gt; 0] Lreg(t,t lowast;)。这里的c lowast;是RoI的地面标签(c lowast; = 0表示背景)。 Lcls(sc lowast;)= -log(sc lowast;)是分类的交叉熵损失,Lreg是在[6]中定义的边界框回归损失,t lowast;表示基本事实框。 [c lowast;gt; 0]是一个指示符,如果参数为true,则等于1,否则为0。我们像[6]中那样设置平衡重lambda;= 1。我们将正面示例定义为RoI,其中RoI的交叉点(IoU)与地面实线框至少重叠0.5,否则为负面。
在培训过程中,我们的方法很容易采用在线硬示例挖掘(OHEM)[22]。我们可忽略的每RoI计算可以实现几乎免费的示例挖掘。假设每个图像有N个建议,则在向前传递中,我们评估所有N个建议的损失。然后,我们按损耗对所有RoI(正负)进行排序,并选择损耗最高的B RoI。根据所选示例执行反向传播[11]。因为我们的每RoI计算可以忽略不计,所以与[22]中的OHEM Fast R-CNN可能使训练时间加倍的相反,前进时间几乎不受N的影响。我们在下一部分的表3中提供了全面的时序统计信息。我们使用0.0005的权重衰减和0.9的动量。默认情况下,我们使用单尺度训练:调整图像大小,使尺度(图像的较短边)为600像素[6,18]。每个GPU保留1张图像,并选择B = 128 RoIs作为反向传播。我们使用8个GPU训练模型(因此有效的最小批处理大小为8倍)。我们对R-FCN进行了微调,对VOC的学习率是20,000个小批量为0.001,而10000个小批量为0.0001。为了使R-FCN与RPN共享功能(图2),我们在[18]中采用了4步交替训练,即在训练RPN和训练R-FCN之间交替进行。
推理。如图2所示,计算了RPN和R-FCN之间共享的特征图
(在单比例尺为600的图像上)。然后RPN部分提出RoI,R-FCN部分在RoI上评估类别得分并回归边界框。在推论过程中,我们如[18]中所述评估了300 RoI,以进行公平比较。按照标准做法,使用0.3 IoU的阈值通过非最大抑制(NMS)对结果进行后处理[7]。
大步向前。我们的全卷积架构享受FCN广泛用于语义分割的网络修改的好处[15,2]。特别是,我们将ResNet-101的有效步幅从32像素减少到16像素,从而提高了得分图的分辨率。 conv4阶段[9]之前和之上的所有层(步幅= 16)均保持不变;将第一个conv5块中的stride = 2运算修改为stride = 1,并且通过“ hole算法” [15,2](“ Algorithmeagrave;trous” [16])将conv5阶段上的所有卷积滤波器修改为补偿减小的步幅。为了公平比较,RPN是在conv4阶段计算的(与
图3:人类别的R-FCN可视化(ktimes;k = 3times;3)。
图4:RoI与对象没有正确重叠时的可视化。
R-FCN),就像[9]中使用Faster R-CNN的情况一样,因此RPN不受agrave;trous技巧的影响。 下表显示了R-FCN的烧蚀结果(ktimes;k = 7times;7,无实例挖掘)。 绝招提高了mAP 2.6点。
带有ResNet-101的R-FCN,在VOC 07测试上为conv4,跨度= 16 conv5,跨度= 32 conv5,agrave;trous,跨度= 16 mAP(%)
可视化。在图3和图4中,我们可视化了当ktimes;k = 3times;3时R-FCN学习的位置敏感得分图。这些专门的图有望在对象的特定相对位置上被强烈激活。例如,“顶部中心敏感”得分图在对象的顶部中心位置附近表现出高得分。如果候选框恰好与真实对象重叠(图3),则RoI中的大多数k2个bin都会被强烈激活,并且它们的投票会导致得分较高。相反,如果候选框未与真实对象正确重叠(图4),则RoI中的某些k2
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[608258],资料为PDF文档或Word文档,PDF文档可免费转换为Word
课题毕业论文、文献综述、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。

