
英语原文共 8 页,剩余内容已隐藏,支付完成后下载完整资料
基于灰色预测和马尔可夫模型预测中国的能源需求和自给率
谢乃明
摘要:本文运用新模型预测中国节能政策影响下中国能源生产和消费的发展趋势,采用优化的单变量离散灰色预测模型预测能源生产和消费总量,提出基于二次规划模型的新型马尔可夫方法预测能源生产和消费结构的变化趋势。提出的模型用于模拟2006-2011年中国的能源生产和消费,并预测其2015年和2020年的趋势。结果表明:所提出的模型可以有效地模拟和预测总量和结构能源生产和消费。且通过与回归模型的比较,结果显示在模拟和预测案例时,该模型比回归略好一些。虽然中国的能源消费增长率在节能减排政策的影响下有所下降,但原油和天然气的自给率继续下降的伴随着能源总量消费、天然气和其他能源的比例持续增长。
关键词:能源;能源结构;灰色预测模型;马尔科夫链;能源政策
引言
中国工业化和城市化已经发展到了一个关键阶段,并有望在未来十年或二十年内继续成为中国经济增长的主要动力。但是截止到目前为止中国工业化和城市化进程是以高能耗为代价来推进的。从长远来看,由于其对环境的负面影响和中国有限的资源,这是不可持续的。中国的能源消耗需要从低效率和高消耗的方式转变为高效节能的方式,就必须控制和减少能源消耗的增长率。2006年,中国政府在“十一五”发展规划中加入了节能政策。在该计划中,从2006年到2010年5年内,节能目标设定为每单位GDP能耗节省20%。为了继续实施节能政策,在“十二五”发展规划中节能目标进一步秀高位每单位GDP能耗节省16%(2011-2015年)。考虑到与二氧化碳排放密切相关的环境恶化问题,应减少煤和原油的比例,同时应增加天然气和其他新能源等清洁能源的比例。根据节能政策,2010年和2012年,中国政府分别进行新能源开发计划(2011-2020)和天然气开发计划(2011-2015年)。在这些能源政策的作用下,中国能源生产和消费发展趋势发生显著变化。鉴于这种政策对体制的冲击,有什么能够提供有意义的能源生产和消费预测?未来各种能源如何自给自足?在能源问题中应用了许多预测模型,例如回归分析(RA)、时间序列分析、人工神经网络、半参数方法和非参数方法[1-8]。然而,这些模型通常需要大量观察和复杂的输入因子来进行合理的预测。在节能政策的冲击下,能源系统的总体发展趋势发生了显著变化,现有有限的观测资料无法满足传统方法的要求。为了预测有限数据序列的发展趋势,需要一个使用小数据集的新模型来克服有限的数据可用性。新兴的灰色系统理论(GST)提供了理想的替代解决方案。GST主要关注小样本和信息不足的问题[9,10]。作为我们此前在该领域工作的结果,我们提出了一种优化的单变量离散灰色预测模型来改进GM(1,1)模型[11]。GM(1,1)模型是GST中的主要预测模型,并已成功应用于各种预测问题[12-17]。通过在GM(1,1)模型中累积生成操作来揭示短序列的发展趋势,减弱其随机扰动。事实上,中国的能源政策在过去几十年已经被广泛讨论过[18-24]。GM(1,1)模型及其优化模型已应用于能源问题的分析和预测。例如,Zhou等[25]通过将GM(1,1)与三角函数相结合,开发了一种三角灰色预测方法来预测电力需求。Akay和Atak [26]提高了GM(1,1)模型预测土耳其工业用电量的准确性。Pao和Tsai [27]应用灰色预测模型来预测污染物巴西2008 -2013年的排放和能源消耗。Lee和Tong[28]开发了一种改进的灰色预测模型将残差修饰与遗传编程符号相结合估算并将其应用于能耗预测中。里等[29]应用AGM(1,1)模型预测短期电力消耗与一些亚洲案例并进行比较反向传播神经网络和支持向量的结果回归。灰色模型也应用于二氧化碳排放预测和可再生能源预测[30-37]。虽然灰色预测模型已成功应用于能源需求和消费预测,其应用预测并分析新能源政策下能源生产和消费总量和结构的发展趋势仍有待研究。如前所述,在新能源政策的冲击影响下,能源系统的总体发展趋势发生了变化,适应新条件的现有数据太有限,无法满足传统预测方法的要求。因此,本文旨在构建新模型,模拟和预测中国能源生产和消费总量和结构的新发展趋势,节能政策于2006年制定。该论文的结构如下:在下一节中,对1990年以来中国的能源自给率总量和能源生产与消费结构的历史发展进行了讨论和分析。 然后,方法论部分建立了两个预测模型,分别预测总量和结构的趋势。再基于所提出的模型,模拟和预测中国能源生产总量和消费结构,模拟中国的能源生产和消费自给率和结构,并在本节中比较回归模型,最后得出结论。
数据
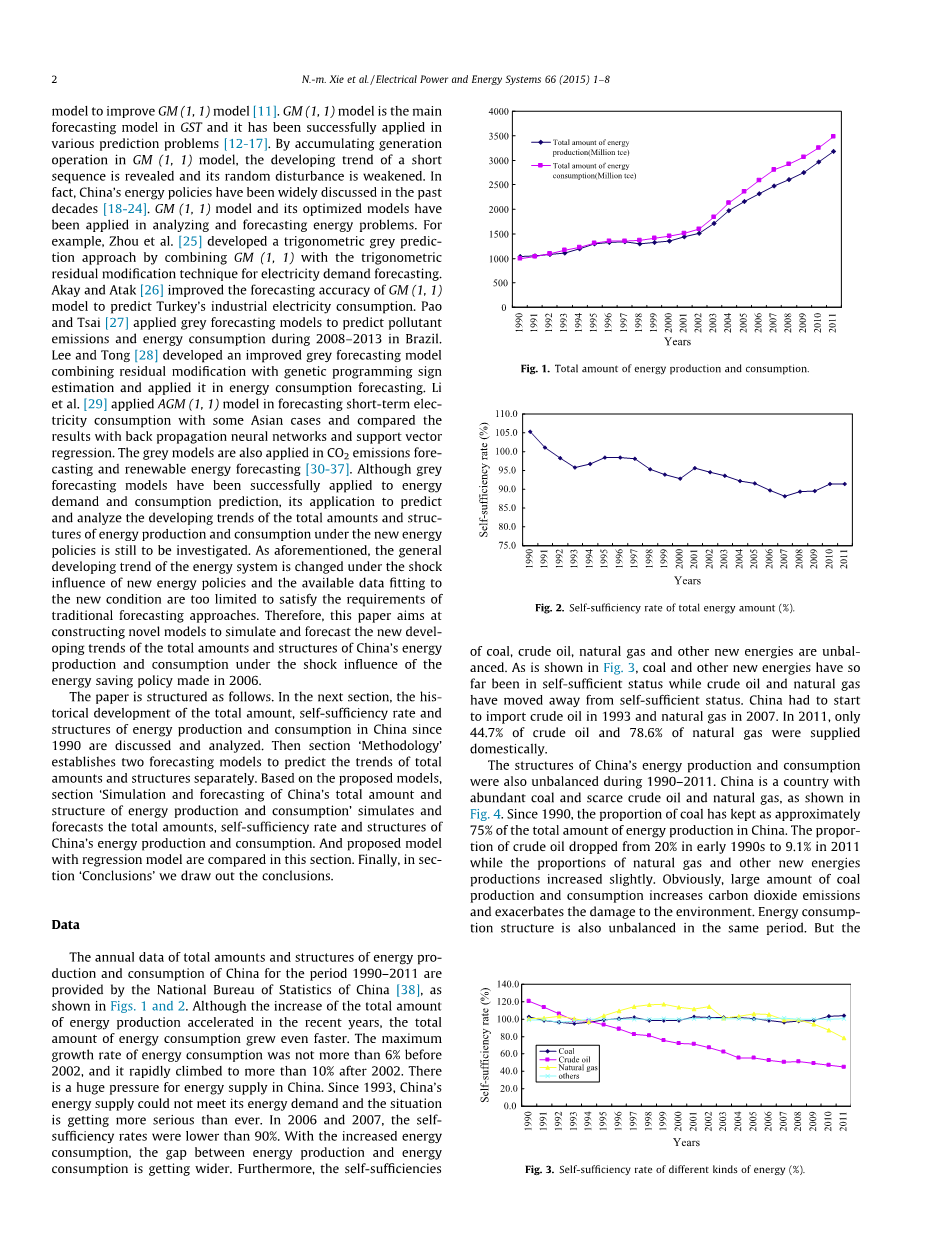
1990 -2011年中国能源生产和消费总量和结构的年度数据是由中国国家统计局[38]提供,如图1和2所示。图1和2虽然近年来能源生产总量增加,生产速度加快,但能源消耗量增长更快。2002年能源消费增长率最大值之前不超过6%,2002年之后迅速攀升至10%以上
对中国的能源供应来说是一个巨大的压力。自1993年以来,中国的能源供应无法满足其能源需求和形势变得越来越严重了。 2006年和2007年,自给率低于90%。随着能量的增加
消费,能源生产与能源之间的差距消费缺口越来越大。而且自给自足的煤炭、原油、天然气和其他新能源是不平衡的。如图3所示,煤和其他新能源一直处于自给自足状态原油和天然气已经不能保持自给自足的地位,从1993年开始中国不得不开始进口原油和2007年进口天然气。在2011年仅供应了国产44.7%的原油和78.6%的天然气。在1990 -2011年中国能源生产和消费的结构期间也是不平衡的。中国是一个拥有的国家丰富的煤炭和稀缺的原油和天然气,如图4所示,自1990年以来,煤炭的比例大致保持不变,占中国能源总产量的75%。原油比例从20世纪90年代初的20%下降到2011年的9.1%,而天然气和其他新能源的比例制作略有增加。显然,大量煤生产和消费增加二氧化碳排放量并加剧对环境的破坏,能源消费结构在同一时期也是不平衡的。但是能源消费结构与此有差别,能源生产结构(如图5所示)煤炭消费比例逐渐减少几乎快下降,在此期间的比例为8%,2011年从76.2%降至68.4%。原油的比例保持在20%。,新能源的比例在2011年增加到8%,2005年天然气消费量也开始小幅上升。因此,原油消费量越来越多依靠进口。
方法
优化单变量离散灰色预测模型
中国2006年推出的节能政策具有重要意义,对其能源生产和消费的影响,以及根据以前记录的数据构建的传统统计模型,2006年肯定不会表现出合理的准确性。 2006年以后收集的数据样本太有限,无法制作有意义的统计模型。灰色预测模型是一种有效的方法,用小数据集预测系统发展趋势[11,16]。优化的灰色预测模型(ODGM)已经建立,已解决这样的问题
小样本预测问题。ODGM的基本程序模型总结如下:1.收集中国能源生产总量2.2006-2011消费总量作为原始序列ODGM模型为Eq(1)
(1)
第2步:转型能源生产和消费序列X(1)累积生成运算符序
,可表示为式(2)。
(2)
第3步:如果是能源生产和消费的参数系列,其中
(3)
(4)
通过ODGM模型中的最小二乘法估计的参数序列(在等式(5)中示出)可以在等式1中表示为。
(5)
(6)
其中是B的转置矩阵。考虑迭代数据不完全等于,可修改的项目
用于表示和之间的差异,即参数可以通过最小二乘法求解,其中无约束优化模型为
(7)
步骤4:模拟和的值可以是表示为(8)和(9)。
(8)
(9)
因此,序列是模拟序列,而序列是预测序列。
步骤5:百分比误差(PE)和平均绝对百分比
错误(MAPE)用于比较原始序列和模拟序列。 PE和MAPE定义如下:
(10)
(11)
基于二次规划模型的马尔可夫方法
总能耗由煤,原油,天然气和其他新能源组成。在中国,近年来不仅能源消费总量不断增加,而且能源消费结构也发生了变化。 在天然气和新能源的特殊政策的影响下,天然气和新能源的比例正在上升。而煤和原油的比例正在下降,未来的能源消费结构主要取决于当前的状况而不是其过去的状态,能源消费结构的转变满足均匀马尔可夫属性。因此,提出一种基于二次规划模型的新马尔可夫方法,其命名为QP-Markov模型。 QPMarkov模型的过程总结如下:
第1步:收集年度总能耗量x(t)以及不同能源成分(煤,原油,天然气等)的年能耗量
周期xi(t)(i = 1,2,3,4; t = 1,2,...,n)。
第2步:计算第i个能量成分的比例
(12)
根据(12),我们可以得出能耗结构矢量为
(13)
步骤3:定义不同能量之间的转移概率矩阵
(14)
其中Pij表示比例的一步转移概率属于t期间的第i个能量成分转移到t期中的第j个能量分量。
步骤4:计算公式中的一步转移概率,(14)用二次规划模型。 t 1和t period之间的过度关系表示
(15)
我们知道比例应该满足考虑到实际价值之间的差异和的模拟值,我们必须最小化总差值,我们将二次规划构造为
(16)
然后我们可以得到转移概率值。
步骤5 :(误差分析)定义每个的绝对重量误差(PE)年和平均绝对重量误差(MAE)为
(17)
(18)
步骤6:基于求解的转移概率矩阵和实际能耗结构向量,我们可以预测未来的能源消费结构。
中国能源生产总量和消费结构的模拟与预测
考虑到2006年中国节能政策的影响,这是最新和最重要的能源政策,我们从2006年开始收集原始数据记录以反映能源冲击影响下的新发展趋势储蓄政策。中国能源生产和消费总量的模拟与预测,根据部分中定义的ODGM模型的程序“优化单变量离散灰色预测模型”,我们收集了中国能源总量的序列数据生产(2006-2011)并建立了ODGM模型,该结果参数的值是
预测方程是: (19)
根据(19)我们可以得到总的模拟结果如图所示,2006年和2011年的能源产量在表1中。平均百分比误差是MAPE(%)= 0.52%。 它是一个非常高的模拟精度,所以我们可以使用(19)预测2015年和2020年的能源生产数据。同样,我们使用回归分析模型(RA)来模拟
中国的能源生产总量(2006-2011)得到RA模型:
(20)
显然,t,F和R2值符合RA模型的预测,获得2006年和2011年总能量产生量的模拟结果在如表1所示。与生产预测类似,我们收集了序列中国能源消费总量的数据2006-2011并建立了ODGM模型,我们得到了参数的值:
预测方程是: (21)
根据(21)我们得到了如图所示的模拟结果表2.平均百分比误差是MAPE(%)= 0.66%。 是一个很好的准确性所以我们使用(21)预测2015年和2020年的能源消耗数据。因此,我们使用回归分析模型(RA)来模拟中国的能源消费总量(2006-2011)得到RA模型:
(22)
显然,t,F和R2值符合RA模型的预测,还获得总能量产生量的模拟结果,在2006年和2011年如表2所示。中国2012年统计公报中主要公布的能源生产和消费的数据被用来验证,
进一步预测ODGM模型的准确性。如图所示表3中,总能量产生和消耗量的百分比误差约为1%。显然准确性非常高。我们应用了构建的ODGM模型和RA模型预测总能源生产和消费量
在2015年和2020年。如表4所示,未来总能源生产和消费量将进一步增加,能源消耗总量将达到4295.97万吨,2015年到2020年再增加33%。能源生产和消费量之间存在差距约为2亿吨,在2015年,差距将在2020年降至接近零。作为一个系统模拟和预测在中国消费能源生
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[20687],资料为PDF文档或Word文档,PDF文档可免费转换为Word
课题毕业论文、文献综述、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。
您可能感兴趣的文章
- 中国碳市场与股票市场之间的非线性相关性:来自分位数一致性和分位数因果关系的新证据外文翻译资料
- 对投资制约因素的融资随机前沿分析:台湾金融自由化的案例外文翻译资料
- 并购类型及其对经营业绩的影响:《印度经验》外文翻译资料
- 空气质量对房价的影响:来自中国淮河政策的证据外文翻译资料
- 以绿色金融促进贵州省发展研究外文翻译资料
- 绿色信贷政策对污染密集型企业技术创新的影响一一来自中国的证据外文翻译资料
- 煤矿风险管理-波兰和捷克硬煤矿行业的系统建议外文翻译资料
- 中小企业融资在发展商业环境和经济增长中的作用:来自越南科技型中小企业的经验证据外文翻译资料
- 金融发展与经济增长:面板数据来自金砖五国外文翻译资料
- 使用区块链的供应链融资:对销售时尚产品的供应链的影响外文翻译资料

