
英语原文共 4 页,剩余内容已隐藏,支付完成后下载完整资料
K-最近邻的快速协同过滤
Youngki Park,Sungchan Park和Sang-goo Lee
计算机科学与工程学院
首尔国立大学
韩国,首尔
{ypark,baksalchan,sglee} @europa.snu.ac.kr
Woosung Jung
计算机工程系
忠北国立大学
韩国,清州
wsjung@cbnu.ac.kr
摘要:传统的基于用户/基于物品的协同过滤算法计算一个用户所有没看过的物品偏好。 虽然这种方法有助于评估使用均方根误差的各种算法的准确性,但它耗费了相当长的时间来推荐物品给用户。 在本文中,我们提出了一种使用k-最近邻图的快速协同过滤算法。 算法不仅仅计算最近的k个邻居的物品偏好,它也通过在贪婪过滤的基础上用更少的时间计算k-最近邻图来缩短执行时间。实验结果表明,我们的方法在不牺牲精度的情况下,它的预处理时间和查询的算法处理时间优于传统的基于用户/基于项目的协作过滤算法。
关键词:快速协同过滤,实时推荐,k-最近邻图,贪心过滤。
第一章 绪论
基于用户的协同过滤算法是有效的方法来为用户推荐有用的东西,该算法基于一个假设:用户喜欢可能兴趣类似的用户喜欢的物品。更具体地说,当用户需要推荐时,基于用户的协同过滤方法[1]计算用户对所有没见过物品的首选项是根据类似用户对这些物品的偏好。同样,基于物品的协同过滤方法[2]是根据类似物品来计算用户对所有未见过的物品。
这些领域的早期研究提出了高质量电影推荐算法,只能推荐最流行的电影或高评价电影[3]。然而,预测所有未分级的电影也是必需的。虽然这种方法有助于评估使用均方根误差方法的算法,这样做占用大量的查询处理时间。此外,预计算时间也很长,特别是基于用户的协作过滤,因为它必须计算所有用户之间的相似性值。
本文提出了一种快速的协同过滤方法,使用k-最近邻图的算法。这个算法不仅能预测k个最近的物品,它也缩短了执行时间,通过贪婪过滤算法在短时间内计算k-最近邻图用较少的时间计算k-最近邻项图的时间。我们证明了我们的方法在预处理时间和查询处理时间上优于传统的基于用户/基于项目的协同过滤算法,而不牺牲精确度。
第二章 相关工作
基于用户的协同过滤算法计算用户偏好通过类似用户对这些物品的偏好。假设我们使用movielens数据集向用户推荐电影项目I的活动用户U的预测评级定义如下[1]:
这里,k表示邻居的数量,ru和rv是用户U和邻居V的平均评分。在另外,sim(u,v)是u和v之间的相似性。使用皮尔逊相关系数作为基于用户的协同过滤算法的相似度:
在这个等式中,m是联合评级电影的数量。
基于物品的协同过滤算法预测用户偏好是根据历史购买物品来预测的。以同样的方式,预测评级定义如下[2]:
注意,我们使用调整后的余弦相似性作为基于物品的协同过滤相似性度量:
这里,m表示本例中的共同评估者数量。
请注意,用户u的k-最近邻不相同这些协同过滤算法中有最高相似值的k-最近邻。在基于用户的协同过滤算法,它们被定义为Knearest用户,他们对项目I进行了评级,而在于项目的情况下协同过滤算法,它们被定义为Knearest物品,已经被用户U评级。
该领域的早期研究表明算法产生的电影推荐结果相比基线算法有很高的质量,基线算法只推荐最受欢迎的电影或高评价的电影。然而,这些类型的算法消耗了大量的资源预处理时间和查询量处理时间;作为一个预处理步骤,基于用户和物品的协同过滤算法为用户逐个准备相似度矩阵和L-最近项图。当希望推荐时,两种算法都必须预测所有未评分的电影。在第三节中,我们提出处理这些问题的新方法。
第三章 实时推荐
我们的方法包括两个主要步骤:第一,我们基于贪婪过滤近似计算k-最近项图[4]作为预处理步骤。其次,我们使用我们的非规范化余弦邻域修订版向用户推荐物品。
3.1、K-NN图表结构
k-最近邻图的构造是一项任务,其中包括查找与每个节点最相似的K个节点。在本中,我们假设一个节点是一个电影。其中一个构造k-nn图的最简单方法是计算所有节点之间的相似性并提取每个节点的相似节点。尽管它很简单,但是蛮力法需要O(n2)时间复杂性,即与大量的数据交互可能负担过重。解决这个问题的另一种方法是使用户矩阵进行反向索引。然而,这种方法也不是足以处理大量高维数据。
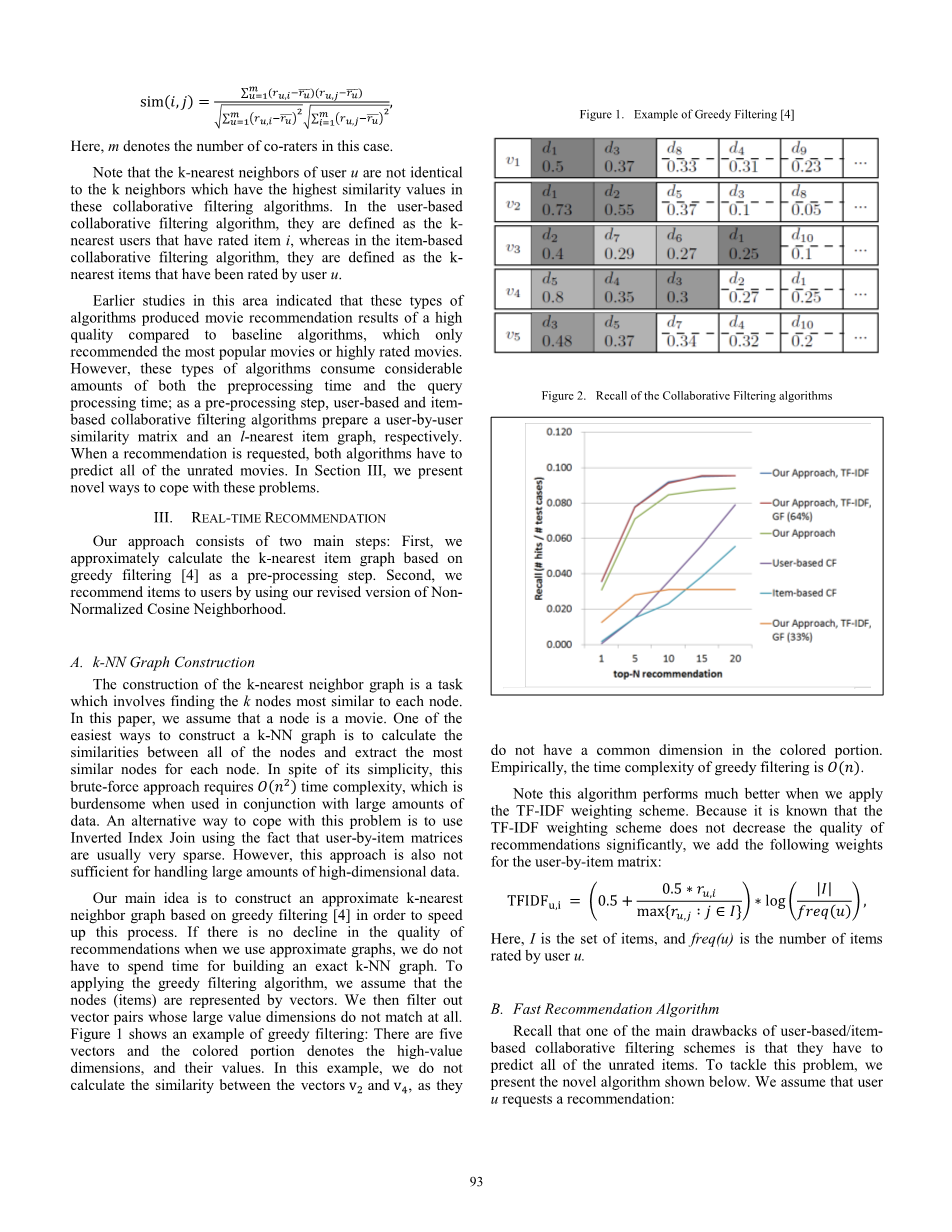
我们的主要想法是构造一个基于贪婪过滤的近似的k-最近邻域图[4]以提高这个过程的速度。如果当我们使用近似图时,质量没有下降,我们不必须花时间构建精确的k-nn图。为应用贪婪过滤算法,我们假设节点(项)由向量表示。然后我们过滤掉其大值维度完全不匹配的向量对。图1显示了贪婪过滤的一个例子:有五个向量和彩色部分表示高值尺寸及其值。在这个例子中,我们没有计算向量v2和v4之间的相似度,因为它们在有色部分没有公共维度。经验上,贪婪滤波的时间复杂度为O(n)。
图1 贪婪过滤示例[4]
注意,当我们应用TF-IDF加权方案时,此算法性能要好得多。因为众所周知TF-IDF加权方案不会降低推荐质量。值得注意的是,我们对于用户按项目矩阵增加了以下权重:
这里,i是一组物品,freq(u)是按用户U评级物品数。
3.2、快速推荐算法
回想一下,基于用户/物品的协同过滤方案的主要缺点之一是它们必须预测所有未分级的项目。为了解决这个问题,我们提出如下所示的新算法。我们假设用户U希望推荐:
1)对于所有未分级物品i,清空k-最近项目列表。
2)对于所有分级物品i,将i添加到其k-最近邻居的所有列表中。
3)对于所有未分级物品i,如果其k-最近邻居大于k,全部删除,最类似的K邻居除外。
4)然后,预测只有k-最近邻居的未分级物品,如下所示:
sim(i,j)是余弦相似性度量,定义如下:
从这个算法可以知道,如果物品i最接近的一个邻居是第j项,那么j的最近的一个邻居是i,因为逐项矩阵通常是稀疏的,这种方法可以减少预测未分级物品的计算成本。
第四章 实验
我们使用MovieLens数据集作比较。有1000209评分3952电影 6040用户,在本数据库。我们使用由cremonesi等人提出的推荐系统的测试方法[ 3 ]。我们把评分分成两组。一组数据是用于我们的训练集(98.6 %的额定值),和另一组数据集是用于预测集(1.4 %的额定值)。测试集包括五星级不流行物品(物品数的99.65 %)。然后,对于由用户U在测试集的每个M评分电影,我们随机选择1000部电影未分级的U,然后推荐前10个;如果我们我们推荐m,我们把它作为一个点击。最后,我们评估这个召回率如下:
我们考虑了六种算法进行比较:基于用户的CF实现了Herlocker等人的工作[1];基于项目的CF实现了Sarwar等人的工作[2];我们的方法只实现快速推荐算法在第III.B节,我们的方法中,TF-IDF适用电影数据集的TF-IDF加权方案,并且实现快速推荐算法。最后,我们的方法,tf-idf,gf(64%)和我们的方法,tf-idf,gf(33%)实施本文提出的所有方法。括号内的百分比表示生成的k-最近邻图。们可以改变参数值,在k-最近邻图的构造。当然,在那里是时间和质量之间的平衡。
图2 协作过滤算法回顾
图2显示,在召回率方面,我们的方法优于基于用户/基于项目的协同过滤。也就是说,评级预测越少,结果越好。当我们将tf-idf加权方案应用于我们的方法时,推荐质量略有提高。当我们使用近似k-nn图,而不是精确的k-nn图,精度为33%,召回率显著降低。上另一方面,当我们使用图的精确度为64%。
图3 协同过滤算法的执行时间
图3显示了这些算法的比较结果在预处理时间和查询处理方面(推荐)100次查询的时间。显然,我们方法明显优于现有方法预处理时间的条件。还有,在这个图中尽管我们方法的查询执行时间和基于物品的协同过滤算法之间的不同效果不太明显,这些差异随着节点数量的增加而增加。
第五章 结论
本文提出了一种快速的协同过滤方法:使用k-最近邻图的算法。此算法不仅只预测k-最近的用户偏好,而且它将执行时间缩短了,通过贪心过滤用更少的时间计算k-最近邻物品。
实验结果表明,我们的推荐算法比传统的基于用户/基于物品的协同过滤算法快得多,而且它还产生质量更好的推荐结果。
致谢
这项工作得到了韩国国家研究基金会(NRF)的支持,由韩国政府资助(MSIP)(编号20110017480)。这项研究是由基础科学研究计划通过韩国国家研究基金会(NRF)资助科学、信息与通信技术与未来规划部(NRF2012R1A1A1043769)。
参考文献
[1] J. Herlocker, J. Konstan, A. Borchers, and J. Riedl. An Algorithmic Framework for Performing Collaborative Filtering. In SIGIR rsquo;99, pages 230-237, 1999.
[2] B. Sarwar, G. Karypis, J. Konstan, and J. Riedl. Item-based Collaborative Filtering Recommendation Algorithms. In WWW rsquo;01, pages 285-295, 2001.
[3] P. Cremonesi, Y. Koren, and R. Turrin. Performance of Recommender Algorithms on Top-N Recommendation Tasks. In RecSys rsquo;10, pages 39- 46, 2010.
[4] Y. Park, S. Park, S. Lee, and W. Jung. Scalable k-nearest neighbor graph construction based on Greedy Filtering. In WWW rsquo;13, pages 227-228, 2013.
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[19982],资料为PDF文档或Word文档,PDF文档可免费转换为Word
课题毕业论文、文献综述、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。

